【Webスクレイピング】錦織圭実況掲示板のデータ記録(サーブコースや速度など)を抽出してまとめてみました
公開日:
最終更新日:2019/01/20
2019/01/20
きっかけはツイッターでの下記やりとりから。
(私=おたこ@otakoma)
赤黄色さん @sna15694 のサーブのデータはかなり貴重と思われます。コースと、回転の種類まで入ってますから。
— netdash@鼻血ブログ (@netdash) 2018年4月26日
— netdash@鼻血ブログ (@netdash) 2018年4月26日
良いですよ、というか寧ろ歓迎します。
どの様な分析になるか楽しみです。これからの記録方法ですが、昨年辺りからサーブの回転ではなく、スピードを記録するようにしていましたが、回転を記録するように戻した方が良いですかね?(両方は無理)
— 橙 (@sna15694) 2018年4月27日
掲示板を確認してみると、サーブコースや速度やポイントの勝ち負け(〇×)がほとんどのポイントで記録されていて。
素晴らしい。是非データベースなどデータ分析をしやすい形にしてみたいなと。
ということでスクレイピングでデータを自動収集してスプレッドシートにまとめてみました。
そのやり方について簡単に説明したいと思います。
便利なWebスクレイピングだが、注意も必要
Webスクレイピングとは、Web上の情報を自動で収集する技術のことを言います。
一度プログラムコードを書けば、ボタン一つでページを巡回してデータを決めたルールに則って自動抽出してくれるので非常に便利です。
ただし、サーバに負荷をかけない、著作権に気を付けるなど注意も必要です。
私は以下を読みました。
Webスクレイピングの注意事項一覧
抽出したデータはcsvファイル(スプレッドシート)で保存
↓は保存したスプレッドシートのスクリーンショットです。

データ数は、2016/4バルセロナ以降の70試合5734ポイント分です。
下記項目をデータとして抽出しています。
・AceDbF エース、ダブルフォルトなど
・Cource サーブコース(wide center body)
・FirstSecond 1stサーブか2ndサーブか
・OpponentPlayer 対戦相手
・Set 何セット目か
・Speed サーブ速度
・TotalGame 何ゲーム目か
・Tournament 大会名
・WinLose 〇⇒Won ×⇒Lost
・ScoreServer ScoreReturner データ記録時のスコア
・Side DeuceサイドかAdサイドか
データ抽出方法について
データ抽出ですが、
ページを巡回して、下記ルールをコードに書いてサーブデータを抽出しました。
(プログラムコードは最後に記載してます)
・赤黄色さんのコメントだけを抽出
・抽出したコメントを各セット毎に分類
・正規表現を用いて文章をゲーム、ポイント毎に区切る
赤黄色さんのコメントだけを抽出
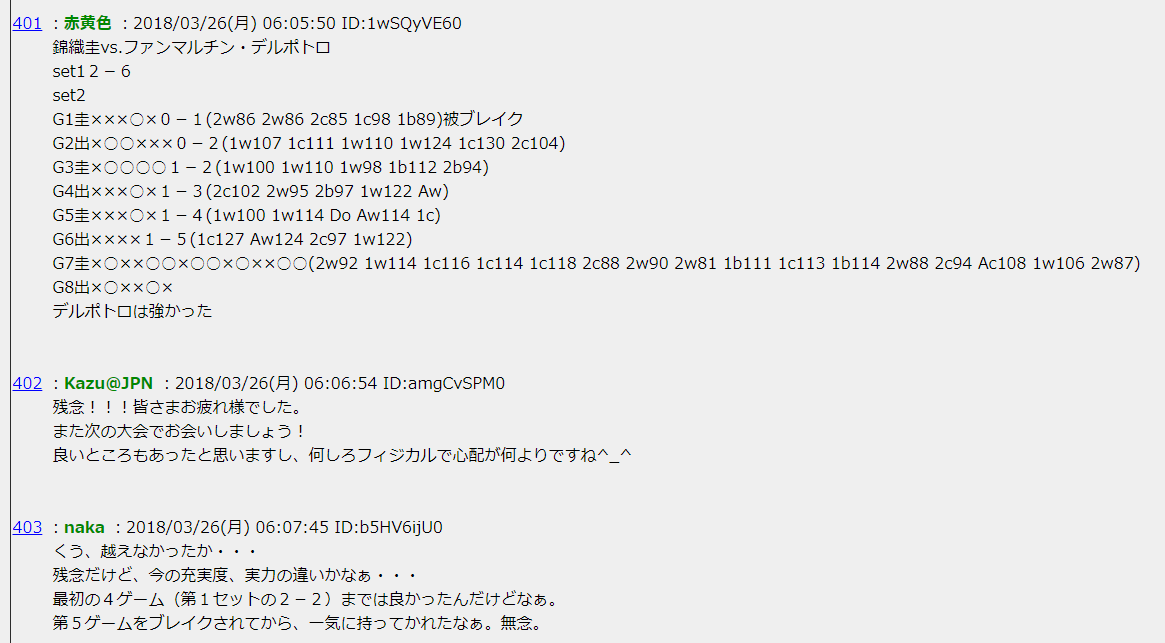
↓は掲示板のスクリーンショットになり、赤黄色さん以外にも多くの方がコメントを書いてます。
基本的には赤黄色さんがサーブデータを記録してくれているので、赤黄色さんのコメントだけを抽出するようにしました。
抽出したコメントを各セット毎に分類
コメントの冒頭にコメントが第何セットの内容なのかわかるような書き方をしてくれているので、何セット目のコメントかでデータを分類しました。
(例)
set1 2-6
set2
と書いてあれば、set2の2の数字を抽出して、コメント内のデータ全てのデータで、setに2を格納するようにします。
正規表現を用いて文章をゲーム、ポイント毎に区切る
各ゲーム毎の情報が、↓のように1行でまとめて書かれています。
G1圭〇×〇〇〇1-0(1w1662c1522c1482c1481c)
この例でいくと、
G1:1ゲーム目
圭:サーバー
〇×〇〇〇〇:勝ち負けが順番に書かれてます。
1-0:ゲーム後のゲームカウント
(1w1662c1522c1482c1481c):サーブの情報が順番に書かれています。
1w166 2c152 2c148 2c148 1c と分割でき、1w166は1stサーブ、コースはワイド、166km/hとなります。
これらを、正規表現という手法でゲーム、サーバー、etc、それぞれの項目を分割して抽出し、データとして格納していきました。
↓のような正規表現を使ったコードです。

正規表現の基本的な考え方については下記をみるといいと思います。
サルにもわかる正規表現
リンク先では正規表現について、
「なぜこの表現方法が有名なのかといえば、この表現方法を利用すれば、たくさんの文章の中から容易に見つけたい文字列を検索することができるためです」
と書かれています。
これ以上の細かい説明は省略しますがデータの抽出ルールをコードに書いたら、あとはページを巡回して自動収集させてデータを格納させました。
他にも空白削除など細かい処理はいくつかやってますが、最後に記載したプログラムコードをみていただければわかるかと思います。
全体の傾向をATPデータと比較してみた
データ収集したら、
まずはATPサイトのServe&Return Trackerの錦織選手のデータと比較してみました。
全体の傾向としてはだいたい合っていそうです。
錦織圭実況掲示板のサーブデータ(@sna15694さん記録)をまとめさせていただきました。2016/4バルセロナ以降の70試合5734ポイント分のデータ。ATPサイトのS&Rトラッカーのコース率ポイント率のデータと比較し、傾向はだいたいあっているかなと。サーブ速度や各試合の傾向も確認できるので貴重なデータ pic.twitter.com/swwsqJSHfF
— おたこ (@otakoma) 2018年5月3日
データのビジュアライズとか
収集したデータを使って、BIツール(redashとかtableau)などでビジュアライズさせるようなことできないかなあと、いろいろ試したりしています。
せっかくのデータなので良い形で公開できないかなと。
やるとしたらデータをAWSなどクラウド上に置く必要があるんですけど、従量課金なのでアクセス多いと大金を払う羽目になりそうで怖く。
いいやり方ないかなあ。
コードについて(Python)
githubで公開してます。
# coding: UTF-8
import re
import unicodedata
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import lxml.html
import time
def createIndex(temp):
for i,r in enumerate(temp):
temp2=re.findall('G([0-9]+)(圭)(.*)([0-9])-([0-9])\((.*)\)',r)
if(temp2[0][0] not in index):
index.append(temp2[0][0])
index2.append(i)
index2[index.index(temp2[0][0])]=i
return index,index2
def devideText(text1):#大会の中で何試合あるかをカウントする
opponentPlayers=list(set(re.findall('.*?vs.*?\n',text1)))
text1=text1.replace(" ","")
text1=text1.replace(" ","")
a=text1.split('\n\n')#コメント毎に抽出
b=[s for s in a if '赤黄色' in s]#赤黄色が含まれるコメントだけ抽出
c=[s for s in b if 'set' in s]#set
d=[s for s in c if 'vs' in s]#vs
array=[]#1⇒選手 2⇒set
for k,kk in enumerate(opponentPlayers):
array_temp=[]
for i in range(9):
array_temp.append("")
array.append(array_temp)
print(opponentPlayers)
for i,ii in enumerate(opponentPlayers):
e=[s for s in d if ii in s]#相手プレイヤー毎に抽出
match = [s for s in e if re.findall('set[0-9][0-9]-[0-9](\([0-9]\))?\n', s)]#set2以降を抽出
#print(match)
for j,jj in enumerate(match):
f=re.findall('set([0-9])[0-9]-[0-9](\([0-9]\))?\n', jj)
print(f)
print(f[0][0])
g=array[i][int(f[0][0])]
g+=jj
array[i][int(f[0][0])]=g
match = [s for s in e if re.findall('set1\n', s)]#set1を抽出
for j,jj in enumerate(match):
g=array[i][0]
g+=jj
array[i][0]=g
return opponentPlayers,array
def initArray():
totalGame=[]
server=[]
winLose=[]
firstSecond=[]
cource=[]
speed=[]
ad=[]
row=[]
index=[]
index2=[]
opponentPlayer=[]
setArray=[]
tournament=[]
return totalGame,server,winLose,firstSecond,cource,speed,ad,row,index,index2,opponentPlayer,setArray,tournament
url = "サイトのURL"
html = urllib2.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
table= soup.findAll("ul",{"class":"thread-list"})[0]
links = [a.get("href") for a in table.find_all("a")]
df = pd.DataFrame({'Tournament':[],'OpponentPlayer':[],'Set':[],'TotalGame':[], 'Server':[], 'WinLose':[],'FirstSecond':[], 'Cource':[], 'Speed':[], 'AceDbF':[]})
options = Options()
options.set_headless(True)# Headlessモードを有効にする(コメントアウトするとブラウザが実際に立ち上がります)
driver = webdriver.Chrome(chrome_options=options)# ブラウザを起動する
for i,l in enumerate(links):
url=l.replace("/l50","/")
print(i,url)
driver.get(url)# ブラウザでアクセスする
time.sleep(1)
title=driver.find_element_by_class_name('thread-title').text#全体をテクスト情報として入手
text=driver.find_element_by_id('thread-body').text#全体をテクスト情報として入手
text1=unicodedata.normalize('NFKC',text)#全角を半角に変換
text2=re.sub("([0-9])(\.)",r"\1",text1)
text2=re.sub("(Ac)(\.)",r"\1",text2)
text2=re.sub("(Aw)(\.)",r"\1",text2)
text2=re.sub("(Do)(\.)",r"\1",text2)
text2=re.sub("(Dn)(\.)",r"\1",text2)
text2=text2.replace(" ","")
text2=text2.replace(" ","")
opponentPlayers,array=devideText(text2)
for p in range(len(array)):
for s in range(len(array[p])):
totalGame,server,winLose,firstSecond,cource,speed,ad,row,index,index2,opponentPlayer,setArray,tournament=initArray()
temp=re.findall('G[0-9]+圭.*[0-9]-[0-9]\(.*\)',array[p][s])#サーブ記載行をすべて抽出
index,index2=createIndex(temp)
for iii,ii in enumerate(index2):
r=temp[ii]
temp2=re.findall('G([0-9]+)(圭)(.*)([0-9])-([0-9])\((.*)\)',r)
temp4=re.sub(r'([0-9][a-z])',r',\1',temp2[0][5].replace(" ",""))
temp5=re.sub('^,',"",temp4)
temp6=temp5.split(",")
for i,t in enumerate(temp6):
temp7=re.search('[0-9][a-z]',t)
temp8=re.search('[0-9]{3}',t)
temp9=re.search('[A-Z][a-z]',t)
tournament.append(title)
temp10=re.search('vs.(.*?)\n',opponentPlayers[p])
opponentPlayer.append(temp10.group(1))
setArray.append(s+1)
totalGame.append(temp2[0][0])
server.append(temp2[0][1])
if((temp2!=None) & (len(temp2[0][2])>i)):
winLose.append(temp2[0][2][i])
else:
winLose.append("")
if(t!=None):
firstSecond.append(t[0])
else:
firstSecond.append("")
if(len(t)>1):
cource.append(t[1])
else:
cource.append("")
if(temp8!=None):
speed.append(temp8.group(0))
else:
speed.append("")
if(temp9!=None):
ad.append(temp9.group(0))
else:
ad.append("")
df_add = pd.DataFrame({'Tournament':tournament,'OpponentPlayer':opponentPlayer,'Set':setArray,'TotalGame':totalGame, 'Server':server, 'WinLose':winLose,'FirstSecond':firstSecond, 'Cource':cource, 'Speed':speed, 'AceDbF':ad})
df=df.append(df_add)
df.to_csv("nosebleed-data-serve.csv")
driver.close()
driver.quit()
print("end")